Solving the Histogram Bug
What is Tempo?
Tempo is a free-to-play rhythm platformer I published with my friends over at Aestronauts. A major facet of the game is mastering each level to claim a spot on one of the global leaderboards, where players are ranked by their 'Beats Per Minute', or BPM. As a result, we felt it was important to give our players useful metrics to compare themselves with the competition. One such metric is the post-level histogram, intended to show the player a full distribution of player scores from the leaderboard, with their current score and personal record marked for reference.
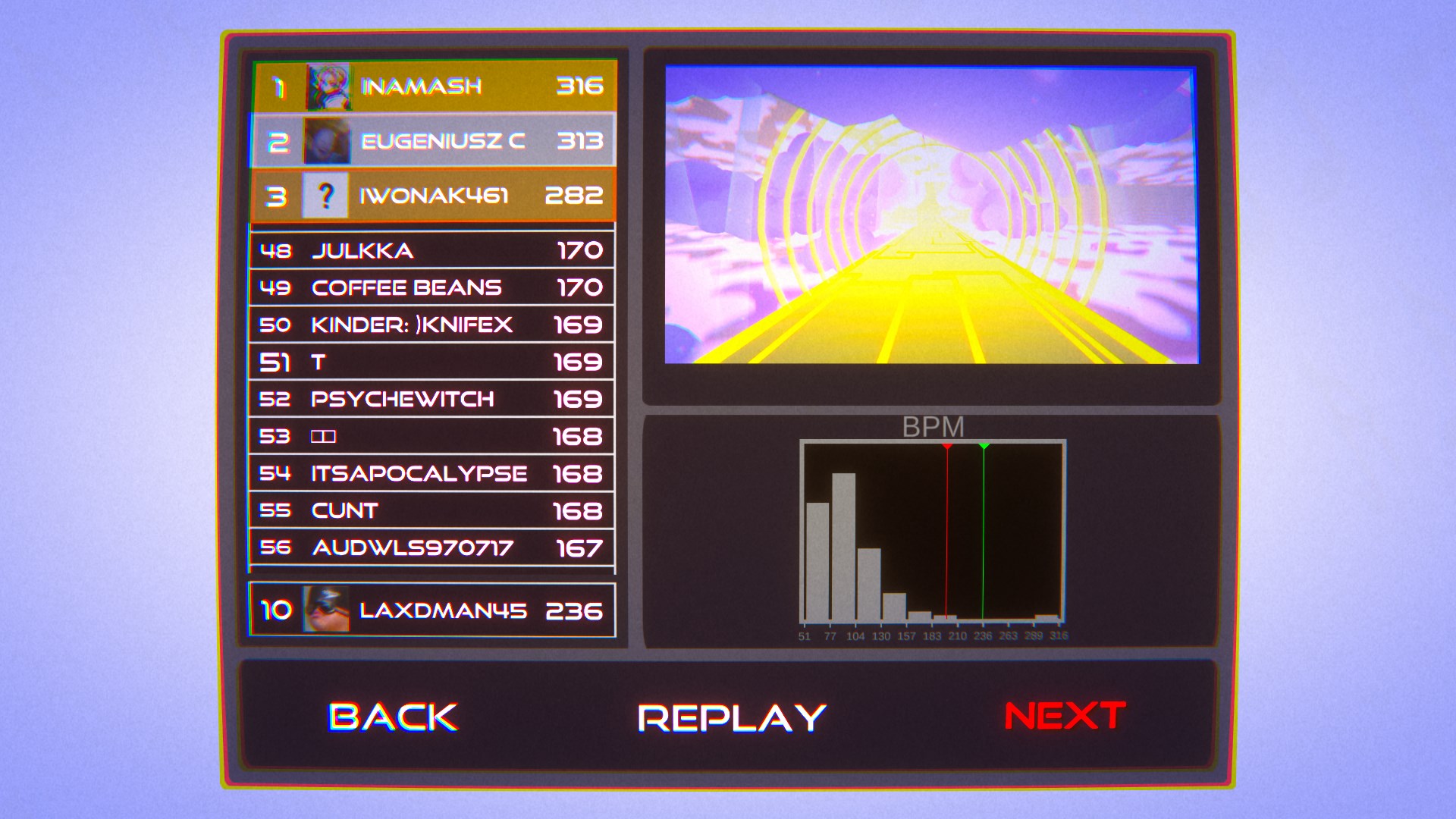
The Issue
This histogram is generated at runtime, right as the player enters the post-game interface.
During the transition, we pull the top 100 entries from the Steam Leaderboard to populate the local leaderboard. Our oversight lay
in using those same scores to populate the histogram as well. Because these are only the top 100 scores, our own score indicator
could be thrown far off the plot, resulting in a blatant visual bug and confusion for the player.
One of our core pillars while developing Tempo was to release a game as bug-free as possible, given the small scope of the game.
As such, we knew this bug had to be addressed right away.
Approach #1
Initially to resolve this, we considered simply pulling the entire Steam Leaderboard down to recreate the full histogram plot every
time the player completes a level. However, as our team anticipated, this turned out to be extremely costly, and on levels with
over 10,000 entries the game would freeze while downloading the entries, and the FPS would tank upon completion, likely due to the
intense memory usage of the several thousand LeaderBoardEntry structs.
🪓 Axed! 🪓
Approach #2
From here, we began considering several routes to address the histogram display bug in a performant manner. One consideration was to
set up a middle-man server using Amazon AWS to act as a buffer between clients and the Steam Leaderboards. This server would
constantly run a script intermittently polling the Steam Leaderboards for each level, and constructing information to define the
histogram plot of the level's leaderboard data. The necessary information would simply be the min score, max score, bucket width, and
number of entries in each bucket. Each client could then query for this small struct of data in order to populate a local copy of the
histogram in real time.
While possible, this solution was definitely not preferable. Not only did it require a significant upfront technical investment to set
up a remote server on a separate platform, but there was also no guarantee that the necessary application would fit nicely within the
processing and memory capacity of a Free Tier Ubuntu Micro-Instance. On top of that, as the Tempo user-base continues to grow, there
is the potential to overwhelm the single lone server, and setting up a load balancing system to handle the potential stress was outside
the particular skill set of our principle engineer (myself). Ultimately, this solution was discarded as too costly and a poor return
on investment.
🪓 Axed! 🪓
Approach #3
The next solution our team discussed was to locally cache all the leaderboard data one time on the players machine, and then update it
intermittently. We determined this to be a poor direction, as we can only run code on a client machine while the game is
active, and optimally we should avoid downloading massive amounts of data while the user is playing. Furthermore, there is now a
tradeoff between performance and keeping the cache up to date.
The real nail in the coffin, however, is that the Steam Leaderboard API doesn't seem to offer a method of retrieving entries based on
the time of creation, meaning this approach is fundamentally flawed. In the end, we deemed this system to be needlessly complex and
potentially non-performant.
🪓 Axed! 🪓
The Final Solution
The final solution was to choose a number N to represent how many leaderboard entries a client is
willing to download. Now, we download every nth entry, where
n = TOTAL_ENTRIES / min(TOTAL_ENTRIES, N), and insert it into the histogram.
This gives us a nice even distribution of the data throughout the plot, with the illusion of a massive amount of
sampled data. Even better, with N as a sliding value, we can conveniently profile and choose an
optimal number of entries to maximize both performance and plot quality. N could even be chosen
dynamically such that it is performant on lower end devices!
🔥 Success! 🔥
